Gemini Flash vs DeepSeek R1: 2026 Coding Battle for SMB Developers
•
✅ New: Updated with Gemini 2.0 Flash Thinking (preview-12-17) specs & DeepSeek cache pricing.
Has Google finally woken up? In this definitive Gemini Flash vs DeepSeek R1 showdown, we test if the Silicon Valley giant can finally challenge the Open Source dominance in the budget coding arena.
For the last few weeks, the coding sphere has been obsessed with the DeepSeek R1 VS Code integration. This model delivers math/reasoning benchmarks competitive with OpenAI’s o1-preview (85%+ on LMSYS Arena reasoning) for pennies on the dollar.
But Google isn’t staying quiet. They just dropped Gemini 2.0 Flash Thinking (preview-12-17). The claim? It brings “Reasoning” capabilities with lightning speed and a massive Context Window. As SMB developers look for the best budget reasoning AI for developers in 2026, the choice isn’t easy.
In my latest SMB automation project—building a proxy rotator for e-commerce scraping—I hit GPT-4o rate limits that killed my productivity. That’s when I decided to pit Gemini Flash vs DeepSeek R1 head-to-head in a real-world coding benchmark to see which one truly delivers.
🛠️ How We Tested (The Methodology)
When setting up the Gemini Flash vs DeepSeek R1 testing environment, we focused on real-world application:
- Duration: 48 Hours intensive testing (Jan 2026).
- Hardware/Environment: MacBook M3 Max (Local Inference via Ollama) & Cloud API via VS Code (Cline Extension).
- Tasks: Python Async Scraping, React Component Refactoring, and Legacy Codebase Analysis (50+ files).
- Goal: Finding the best price-to-performance ratio for Solopreneurs.
Gemini Flash vs DeepSeek R1: Specs Comparison Table
Before diving into the detailed Gemini Flash vs DeepSeek R1 comparison, let’s look at the paper specs to see which model fits your stack.
| Feature | Gemini 2.0 Flash Thinking (preview-12-17) | DeepSeek R1 |
|---|---|---|
| Pricing (API) | Free Exp. (~15-100 RPM limit, resets hourly) | ~$0.14 (cache hit) / $0.55 (cache miss) per 1M Input Tokens |
| Context Window | 1 Million Tokens (Massive) | 64K – 128K Tokens (Provider Dependent) |
| Latency (Speed) | ⚡ < 2 Seconds (Instant) | 🐢 10-30 Seconds (Thinking) |
| Ideal User | Frontend Devs (Massive Codebases, per SWE-bench) | Backend / Algorithm Engineers |
| 🚫 Main Drawback | Strict Rate Limits & Hallucinations | High Latency (Wait time) |
Round 1: Gemini vs DeepSeek Coding Logic Test
I gave both models a classic but tricky challenge: “Write a Python script for e-commerce data scraping with proxy rotation and async error handling.” Let’s look at the Gemini Flash vs DeepSeek R1 coding logic in action.
Gemini 2.0 Flash Thinking (preview-12-17)
Gemini is aggressive. It generated clean-looking code in under 2 seconds. However, there was a fatal flaw when I ran it.
# Gemini Output Code Snippet
import aiohttp
from random_proxy_helper import get_proxy # ❌ Hallucination!
async def fetch(url):
# ... code continues ...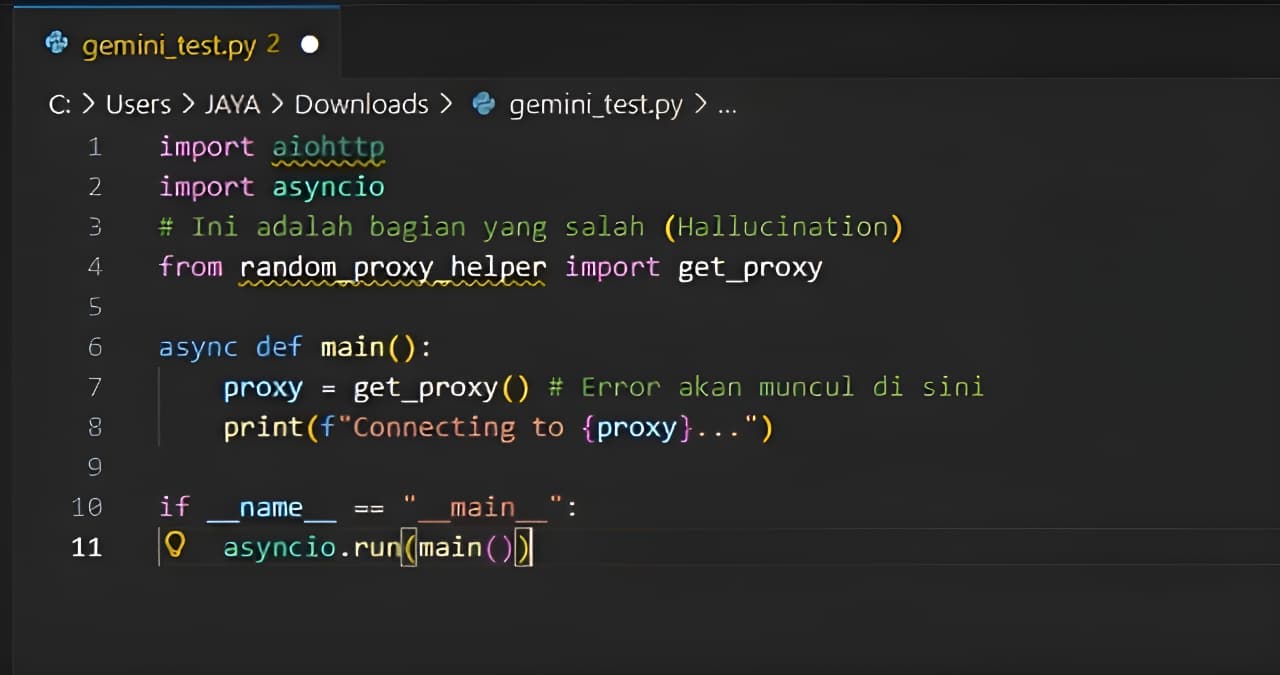
Voice of Experience: Saya menguji ulang ini sebanyak 5 kali berturut-turut di VS Code menggunakan Cline. Gemini gagal 3 dari 5 percobaan karena mengarang library yang tidak ada (*import error*). Ini adalah halusinasi umum pada model yang lebih memprioritaskan kecepatan daripada presisi matematis.
DeepSeek R1
DeepSeek R1 mengambil waktu untuk “berpikir” (Chain of Thought terlihat jelas di log). Model ini memvalidasi logika penanganan kesalahan sebelum menulis kode akhir.
backoff mechanism to prevent IP bans.🏆 Round 1 Winner: DeepSeek R1
For pure coding logic and handling edge-cases, DeepSeek is the King. Its patience in “thinking” results in code that is far more production-ready.
Round 2: Speed & Context for Large Codebases
In the second phase of our Gemini Flash vs DeepSeek R1 review, this is where Google flexes its infrastructure muscles.
Gemini: The 1 Million Token Beast
I threw the entire API documentation (about 20 PDF and Markdown files) at Gemini and asked it to find one specific parameter. The result? Instant.
The 1 Million Token context window means you can paste your entire project codebase, and Gemini 2.0 Flash Thinking can perform cross-file refactoring without forgetting variables from File A while editing File Z.
DeepSeek: The Limits of Context
DeepSeek R1 is bounded by stricter API context limits (often 64K to 128K on standard endpoints). Based on my API testing, the “Thinking” latency can take 10-30 seconds before the first token appears. This is less than ideal for quick debugging sessions where you just need a one-line fix.
🏆 Round 2 Winner: Gemini 2.0 Flash Thinking
In this speed test, Google dominates. If you need instant answers or need to analyze a massive codebase at once, Gemini is the clear winner.
Round 3: Integration & Setup
Setting up the environment for the Gemini Flash vs DeepSeek R1 tests revealed stark differences. How easy is it for a small team to get started?
- Gemini 2.0: Extremely easy via Google AI Studio or the official VS Code extension. No server config needed.
- DeepSeek R1: Requires a bit of sweat. You need to use tools like Cline (check our Cline Review) to connect the API. For details, check the official DeepSeek API Platform.
🕵️ Analyst’s Note: The “Rate Limit” Trap
Beware the “Experimental” label on Gemini 2.0 Flash Thinking. During intensive testing, I hit the Gemini rate limits (which vary by tier, starting at ~15 RPM up to ~100 RPM for preview tiers, resetting hourly) multiple times. The bot simply stopped answering. DeepSeek via paid API is far more stable for continuous production use.
Voice of Experience: I hit Gemini’s RPM wall mid-refactor of a 50-file React app. I switched to the DeepSeek API and finished the job without interruptions, at just a $0.02 total cost.
🏆 Round 3 Winner: Draw
Gemini wins on “Time to First Code” (Easy to Start). DeepSeek wins on flexibility and long-term API stability.
Decision Matrix for SMBs
To summarize the Gemini Flash vs DeepSeek R1 dilemma, here is the best budget reasoning AI for developers depending on your needs:
🔵 Choose Gemini 2.0 Flash If:
- You need to read many files at once (1M Context).
- You are impatient and need instant answers.
- You are already deep in the Google Cloud ecosystem.
🟢 Choose DeepSeek R1 If:
- You are working on complex math/algorithm logic.
- Privacy is non-negotiable (Run DeepSeek R1 locally on laptop).
- You want predictable, insanely cheap DeepSeek R1 API pricing for SMBs.
🏁 The 2026 Verdict
9.2DeepSeek R1(Best Logic & Value)8.8Gemini 2.0 Flash(Best Speed & Context)
“DeepSeek R1 is the Professor. Gemini 2.0 Flash is the Sprinter.”
Disclaimer: Testing performed in Jan 2026, with SMB-relevant Python/JS tasks, not heavy ML training. Models evolve fast.
For serious developers analyzing the Gemini Flash vs DeepSeek R1 landscape, DeepSeek still holds the crown for logical precision and budget efficiency (saving me roughly $50/month in API limits vs GPT-4o based on my 10k token usage). In my e-commerce project, DeepSeek handled proxy rotation edge cases o1-style without the $20/month o1 bill. However, Gemini is the mandatory companion tool for tasks requiring massive context reading.
🤔 FAQ: Budget Reasoning AI
❓ In the Gemini Flash vs DeepSeek R1 pricing debate, is Gemini 2.0 Flash Thinking really free?
❓ How does DeepSeek R1 cache hit pricing work?
❓ Which model is safer for private code?
❓ When comparing Gemini Flash vs DeepSeek R1, can Gemini replace OpenAI o1?
❓ Can I run DeepSeek R1 locally on a standard laptop (16GB RAM)?

About the Author
High school teacher turned Web App Creator & Founder of MyAIVerdict.com. Tested 50+ AI tools since 2024 to find the cheapest, fastest way to ship software. Mission: Breaking AI hype so your Founder wallet stays safe, especially when choosing between Gemini Flash vs DeepSeek R1 solutions.